每次訓練後,LSTM 都會「忘記」前一段的資訊。
這就像你在讀小說時:
每讀 50 頁就完全忘光前面劇情,這樣模型沒辦法學會長期的關聯性。例如:股價在一週前的趨勢仍會影響今天。
一句話的語意往往取決於前幾句上下文。要解決這個問題,就要用上 stateful LSTM。
LSTM 其實內部有兩個核心狀態:
h_t:隱藏層狀態(short-term memory)
c_t:cell 狀態(long-term memory)
每次呼叫 self.lstm(x) 時,PyTorch 會回傳:
out, (h, c) = self.lstm(x, (h0, c0))
預設情況下,這些狀態會在每個 batch 被重置為 0。
而 stateful training 的核心概念就是:「不要清空它,而是把上一段的狀態接續下去。」
讓我們用 sin 波來示範,但這次把波拆成多段小序列。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 產生 sin 波
data = np.sin(np.linspace(0, 100, 1000))
seq_len = 50
batch_size = 10
# 切割資料成 batch
def create_batches(data, seq_len, batch_size):
batches = []
for i in range(0, len(data) - seq_len, seq_len):
x = data[i:i+seq_len]
y = data[i+1:i+seq_len+1]
batches.append((x, y))
return batches
batches = create_batches(data, seq_len, batch_size)
class StatefulLSTM(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=1, output_size=1):
super(StatefulLSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
self.hidden = None # 這裡用來儲存狀態 (h, c)
def reset_hidden_state(self):
self.hidden = None # 清空記憶(例如每個 epoch)
def forward(self, x):
out, self.hidden = self.lstm(x, self.hidden)
out = self.fc(out)
return out
關鍵差異:
self.hidden 儲存了 (h, c) 狀態。
不會在每個 batch 自動重置。
除非手動呼叫 reset_hidden_state()。
model = StatefulLSTM()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(10):
model.reset_hidden_state()
total_loss = 0
for x, y in batches:
x = torch.tensor(x).unsqueeze(0).unsqueeze(-1).float()
y = torch.tensor(y).unsqueeze(0).unsqueeze(-1).float()
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss/len(batches):.6f}")
每個 epoch 結束前才重置 hidden state,模型可以在 batch 之間「延續記憶」,對長序列特別有用(如語音、氣候、文字生成)。
# 測試連續預測
test_seq = torch.tensor(data[:seq_len]).unsqueeze(0).unsqueeze(-1).float()
preds = []
model.reset_hidden_state()
for _ in range(200):
with torch.no_grad():
out = model(test_seq)
pred = out[:, -1, :].item()
preds.append(pred)
next_input = torch.tensor([[pred]]).unsqueeze(0)
test_seq = torch.cat((test_seq[:, 1:, :], next_input), dim=1)
plt.figure(figsize=(10,4))
plt.plot(data, label='True Wave')
plt.plot(range(seq_len, seq_len+len(preds)), preds, color='orange', label='Predicted')
plt.legend()
plt.title("Stateful LSTM Sine Prediction")
plt.show()
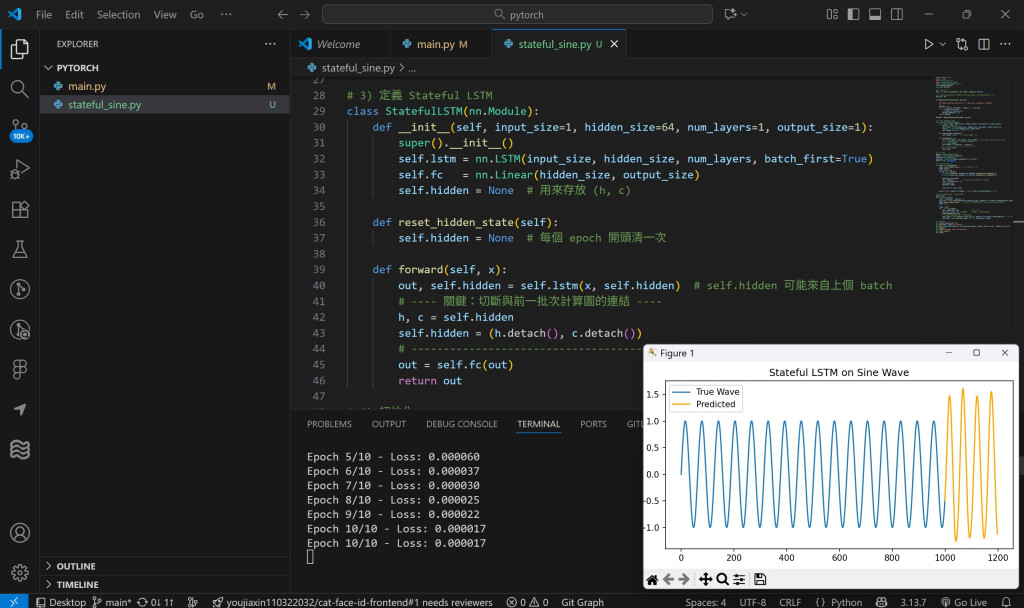
結果:
🔸 模型能「接續」前面的波,不再從零開始學習。
🔸 波形預測更平滑、更長期穩定。


 iThome鐵人賽
iThome鐵人賽